
自编码器是一种数据压缩算法,其中数据的压缩和解压缩函数是数据相关的、从样本中训练而来的。大部分自编码器中,压缩和解压缩的函数是通过神经网络实现的。
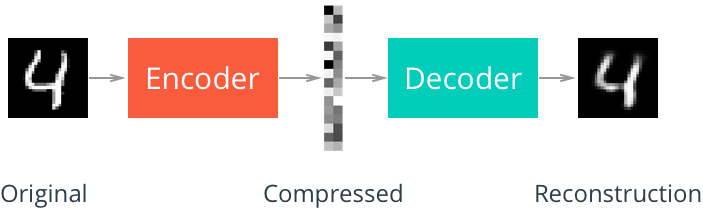
搭建自编码器
一、导入MNIST数据集(灰度图,像素范围0~1)
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Lambda, UpSampling2D from tensorflow.keras.optimizers import Adam from tensorflow.keras.models import Model (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train/255., x_test/255. |
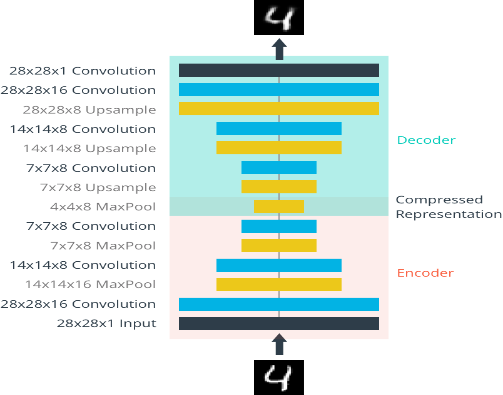
二、搭建网络
需要注意的是模型在解码部分使用的不是反卷积Deconvolution,而是上采样+卷积(参考文献)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
### Encoder input = Input(shape=(28,28,1)) #28x28x1 conv_1 = Conv2D(16, kernel_size=3, padding="same", activation="relu")(input) #28x28x16 maxpool_1 = MaxPool2D(pool_size=2, strides=2, padding="same")(conv_1) #14x14x16 conv_2 = Conv2D(8, kernel_size=3, padding="same", activation="relu")(maxpool_1) #14x14x8 maxpool_2 = MaxPool2D(pool_size=2, strides=2, padding="same")(conv_2) #7x7x8 conv_3 = Conv2D(8, kernel_size=3, padding="same", activation="relu")(maxpool_2) #7x7x8 encoded = MaxPool2D(pool_size=2, strides=2, padding="same")(conv_3) #4x4x8 ### Decoder upsample_1 = Lambda(lambda x: tf.image.resize(x, size=(7,7), method="nearest"))(encoded) # 7x7x8 conv_4 = Conv2D(8, kernel_size=3, padding="same", activation="relu")(upsample_1) #7x7x8 upsample_2 = UpSampling2D(size=2, interpolation='nearest')(conv_4) # 14x14x8 conv_5 = Conv2D(8, kernel_size=3, padding="same", activation="relu")(upsample_2) #14x14x8 upsample_3 = UpSampling2D(size=2, interpolation='nearest')(conv_5) # 28x28x8 conv_6 = Conv2D(16, kernel_size=3, padding="same", activation="relu")(upsample_3) #28x28x16 decoded = Conv2D(1, kernel_size=3, padding="same", activation="sigmoid")(conv_6) #28x28x1 auto_encoder = Model(input, decoded) ### Optimizer opt = Adam(learning_rate=1e-3) auto_encoder.compile(optimizer=opt, loss='binary_crossentropy') auto_encoder.summary() |
三、训练和验证网络
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
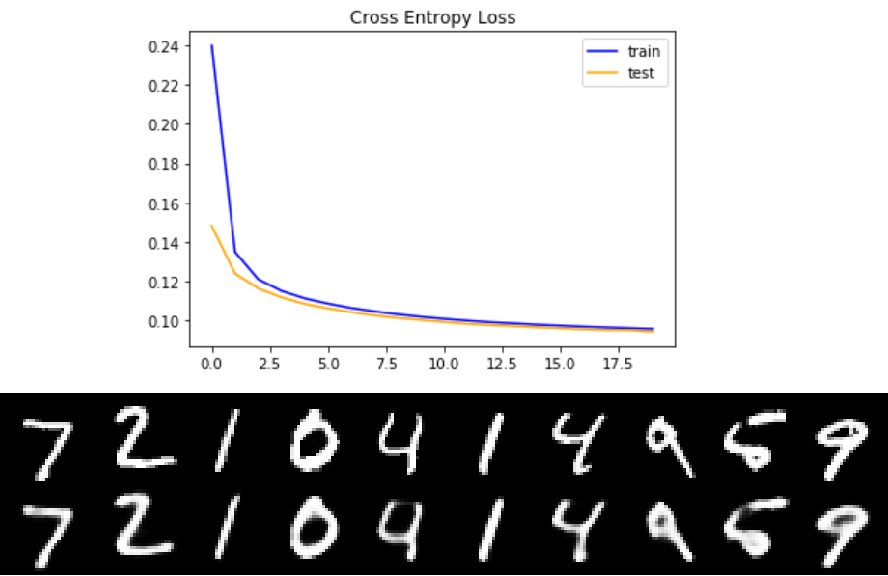
### Train history = auto_encoder.fit(x_train[:,:,:,None], x_train[:,:,:,None], batch_size=200, epochs=20, \ shuffle=True, validation_data=(x_test[:,:,:,None], x_test[:,:,:,None])) plt.title('Cross Entropy Loss') #上图 plt.plot(history.history['loss'], color='blue', label='train') plt.plot(history.history['val_loss'], color='orange', label='test') plt.legend() ### Test decoded_imgs = auto_encoder.predict(x_test[:,;,:,None]) in_imgs, reconstructed = x_test[:10], decoded_imgs[:10,:,:,0] fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4)) #下图 for images, row in zip([in_imgs, reconstructed], axes): for img, ax in zip(images, row): ax.imshow(img, cmap='Greys_r') ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) fig.tight_layout(pad=0.1) ### 输出压缩后的图像 compress = Model(auto_encoder.input, auto_encoder.layers[6].output) #Encoder compressed = compress.predict(x_test[:,:,:,None]) #4x4x8 |
使用自编码器降噪
一、搭建网络(同上但feature map的个数由16-8-8-8-8-16变为32-32-16-16-32-32)
二、训练和验证网络
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
noise_factor = 0.5 #set how much noise we're adding to the MNIST images x_noisy_train = x_train + noise_factor * np.random.randn(*x_train.shape) x_noisy_test = x_test + noise_factor * np.random.randn(*x_test.shape) x_noisy_train, x_noisy_test = np.clip(x_noisy_train, 0., 1.), np.clip(x_noisy_test, 0., 1.) ### Train auto_encoder.fit(x_noisy_train[:,:,:,None], x_train[:,:,:,None], batch_size=200, epochs=100, \ shuffle=True, validation_data=(x_noisy_test[:,:,:,None], x_test[:,:,:,None])) ### Test decoded_imgs = auto_encoder.predict(x_noisy_test[:,;,:,None]) in_imgs, reconstructed = x_noisy_test[:10], decoded_imgs[:10,:,:,0] fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4)) for images, row in zip([in_imgs, reconstructed], axes): for img, ax in zip(images, row): ax.imshow(img, cmap='Greys_r') ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) fig.tight_layout(pad=0.1) |
