该示例所用的数据可从该链接下载,提取码为3y90,数据说明可参考该网页。本文“模型调参”这一部分引用了这篇博客的步骤。关于XGBOOST的算法原理和参数介绍可参考文章GBDT和XGBOOST算法原理。
数据前处理
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.preprocessing import FunctionTransformer, LabelBinarizer from sklearn_pandas import DataFrameMapper from sklearn.pipeline import Pipeline ### 读取数据,拆分训练集和测试集 data = pd.read_csv('Train.csv', encoding = "ISO-8859-1") train, test = train_test_split(data,train_size=0.7,random_state=123,stratify=data['Disbursed']) target = 'Disbursed' predictors_raw = [col for col in train.columns if col!=target] train_X, train_y = train[predictors_raw], train[target] ### 拆分数值特征和类别特征 category_cols = train_X.columns[train_X.dtypes==object].tolist() category_cols.append('Var4') #根据数据说明,Var4虽然为数值类型,但实际为类别特征 numeric_cols = list(set(train_X.columns)-set(category_cols)) ### 查看特征的缺失值比例 nulls_per_column = train_X.isnull().sum() for c in train_X.columns: print('Ratio of missing value for variable {0}: {1}'.format(c,nulls_per_column[c]/train_X.shape[0])) print('-----------------------------------------------------------') #将缺失值较多的特征转化为是否为缺失值的判断 numeric_add = ['Loan_Amount_Submitted_Missing', 'Loan_Tenure_Submitted_Missing', 'EMI_Loan_Submitted_Missing', \ 'Interest_Rate_Missing', 'Processing_Fee_Missing'] numeric_cols = numeric_cols+numeric_add #将生日转化为年龄 numeric_cols = numeric_cols+['Age'] ### 查看类别特征中每个类别的样本个数 counts = dict() for v in category_cols: counts[v] = train_X[v].value_counts() #在类别特征中合并样本个数较少的类别 non_merge_city = [c for c in counts['City'].index if counts['City'][c]>=200] non_merge_sa = [c for c in counts['Salary_Account'].index if counts['Salary_Account'][c]>=100] non_merge_sr = [c for c in counts['Source'].index if counts['Source'][c]>=100] ### 去掉无意义或用处不大的特征 dropped_columns = ['ID','Lead_Creation_Date','LoggedIn','Employer_Name','DOB','Loan_Amount_Submitted', \ 'Loan_Tenure_Submitted','EMI_Loan_Submitted','Interest_Rate','Processing_Fee'] ### 特征工程 ### def preprocess(X): X['Var4'] = X['Var4'].astype(str) #将数值类型转化为类别特征 # 在类别特征中合并样本个数较少的类别 X['City'] = X['City'].apply(lambda x: 'others' if x not in non_merge_city and not pd.isnull(x) else x) X['Salary_Account'] = X['Salary_Account'].apply(lambda x: 'others' if x not in non_merge_sa and not pd.isnull(x) else x) X['Source'] = X['Source'].apply(lambda x: 'others' if x not in non_merge_sr and not pd.isnull(x) else x) # 将生日转化为年龄 X['Age'] = X['DOB'].apply(lambda x: 120 - int(x[-2:])) # 将缺失值较多的特征转化为是否为缺失值的判断 X['Loan_Amount_Submitted_Missing'] = X['Loan_Amount_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0) X['Loan_Tenure_Submitted_Missing'] = X['Loan_Tenure_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0) X['EMI_Loan_Submitted_Missing'] = X['EMI_Loan_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0) X['Interest_Rate_Missing'] = X['Interest_Rate'].apply(lambda x: 1 if pd.isnull(x) else 0) X['Processing_Fee_Missing'] = X['Processing_Fee'].apply(lambda x: 1 if pd.isnull(x) else 0) return X.drop(dropped_columns, axis=1) #去掉无意义或用处不大的特征 ### 填充数值特征缺失值 numeric_imputer = [([feature], SimpleImputer(strategy="median")) for feature in numeric_cols if feature not in dropped_columns] ### 填充类别特征缺失值并进行one-hot encode category_imputer = [([feature], [SimpleImputer(strategy='constant', fill_value='Missing'),LabelBinarizer()]) \ for feature in category_cols if feature not in dropped_columns] ### 合并数值特征和类别特征 numeric_categorical_union = DataFrameMapper(numeric_imputer+category_imputer,input_df=True,df_out=True) ### 建立数据管道 pipeline_data = Pipeline([("preprocessor", FunctionTransformer(preprocess, validate=False)), ("featureunion", numeric_categorical_union)]) train_3 = pipeline_data.fit_transform(train_X) train_3[target] = train_y #train_3为在后续模型调参中使用的数据 |
模型调参
一、建立基础模型并使用early_stop调整迭代次数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import xgboost as xgb ### base model target = 'Disbursed' predictors = [x for x in train_3.columns if x!=target] xgb1 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) ### use early_stop in xgb.cv def get_n_estimators(alg, dtrain, predictors, target, cv_folds=5, early_stopping_rounds=50): xgb_param = alg.get_xgb_params() xgtrain = xgb.DMatrix(dtrain[predictors], label=dtrain[target]) cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds, \ metrics='auc', early_stopping_rounds=early_stopping_rounds, stratified=True) #Print model report: print("\nModel Report") print("Set n_estimators to {0}".format(cvresult.shape[0])) print(cvresult.tail(1)['test-auc-mean']) return cvresult.shape[0] ### get n_estimators n_estimators = get_n_estimators(xgb1, train_3, predictors, target) |
二、调试参数max_depth和min_child_weight
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from sklearn.model_selection import GridSearchCV param_test1 = {'max_depth':range(3,10,2),'min_child_weight':range(1,6,2)} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=5, min_child_weight=1, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch1 = GridSearchCV(estimator = alg, param_grid = param_test1, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch1.fit(train_3[predictors],train_3[target]) print(gsearch1.best_params_) #optimal: {'max_depth':5,'min_child_weight':5} print(gsearch1.best_score_) param_test2 = {'max_depth':[4,5,6],'min_child_weight':[4,5,6]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=5, min_child_weight=5, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch2 = GridSearchCV(estimator = alg, param_grid = param_test2, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch2.fit(train_3[predictors],train_3[target]) print(gsearch2.best_params_) #optimal: {'max_depth':4,'min_child_weight':6} print(gsearch2.best_score_) param_test2b = {'min_child_weight':[6,8,10,12]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch2b = GridSearchCV(estimator = alg, param_grid = param_test2b, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch2b.fit(train_3[predictors],train_3[target]) print(gsearch2b.best_params_) #optimal: {'min_child_weight':6} print(gsearch2b.best_score_) |
三、调试参数gamma并调整迭代次数
|
1 2 3 4 5 6 7 8 9 10 11 |
param_test3 = {'gamma':[i/10.0 for i in range(0,5)]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch3 = GridSearchCV(estimator = alg, param_grid = param_test3, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch3.fit(train_3[predictors],train_3[target]) print(gsearch3.best_params_) #optimal: {'gamma':0.2} print(gsearch3.best_score_) xgb2 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=1000, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) n_estimators = get_n_estimators(xgb2, train_3, predictors, target) |
四、调试参数subsample和colsample_bytree
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
param_test4 = {'subsample':[i/10.0 for i in range(6,11)], 'colsample_bytree':[i/10.0 for i in range(6,11)]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, seed=27) gsearch4 = GridSearchCV(estimator = alg, param_grid = param_test4, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch4.fit(train_3[predictors],train_3[target]) print(gsearch4.best_params_) #optimal: {'colsample_bytree': 0.7, 'subsample': 0.7} print(gsearch4.best_score_) param_test5 = {'subsample':[i/100.0 for i in range(65,80,5)], 'colsample_bytree':[i/100.0 for i in range(65,80,5)]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.7, colsample_bytree=0.7, objective= 'binary:logistic', nthread=4, seed=27) gsearch5 = GridSearchCV(estimator = alg, param_grid = param_test5, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch5.fit(train_3[predictors],train_3[target]) print(gsearch5.best_params_) #optimal: {'colsample_bytree': 0.75, 'subsample': 0.7} print(gsearch5.best_score_) |
五、调试参数reg_alpha
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
param_test6 = {'reg_alpha':[0, 1e-5, 1e-2, 0.1, 1, 100]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0.2, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch6 = GridSearchCV(estimator = alg, param_grid = param_test6, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch6.fit(train_3[predictors],train_3[target]) print(gsearch6.best_params_) #optimal: {'reg_alpha': 0.01} print(gsearch6.best_score_) param_test7 = {'reg_alpha':[0.001, 0.005, 0.01, 0.05]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0.2, reg_alpha=0.01, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch7 = GridSearchCV(estimator = alg, param_grid = param_test7, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch7.fit(train_3[predictors],train_3[target]) print(gsearch7.best_params_) #optimal: {'reg_alpha': 0.01} print(gsearch7.best_score_) |
六、调试参数reg_lambda并调整迭代次数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
param_test8 = {'reg_lambda':[0, 0.01, 0.1, 1, 10, 100]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0.2, reg_alpha=0.01, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch8 = GridSearchCV(estimator = alg, param_grid = param_test8, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch8.fit(train_3[predictors],train_3[target]) print(gsearch8.best_params_) #optimal: {'reg_lambda': 1} print(gsearch8.best_score_) param_test9 = {'reg_lambda':[0.5, 0.7, 1, 3, 5]} alg = xgb.XGBClassifier(learning_rate=0.1, n_estimators=n_estimators, max_depth=4, min_child_weight=6, gamma=0.2, reg_alpha=0.01, \ subsample=0.7, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, seed=27) gsearch9 = GridSearchCV(estimator = alg, param_grid = param_test9, scoring='roc_auc', n_jobs=4, iid=False, cv=5) gsearch9.fit(train_3[predictors],train_3[target]) print(gsearch9.best_params_) #optimal: {'reg_lambda': 1} print(gsearch9.best_score_) xgb3 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=1000, max_depth=4, min_child_weight=6, gamma=0.2, \ reg_alpha=0.01, reg_lambda=1, subsample=0.7, colsample_bytree=0.75, \ objective= 'binary:logistic', nthread=4, seed=27) n_estimators = get_n_estimators(xgb3, train_3, predictors, target) |
七、减少学习率(learning_rate)并调整迭代次数,通过函数get_n_estimators的输出信息比较算法是否有改进
|
1 2 3 4 |
xgb4 = xgb.XGBClassifier(learning_rate=0.01, n_estimators=5000, max_depth=4, min_child_weight=6, gamma=0.2, \ reg_alpha=0.01, reg_lambda=1, subsample=0.7, colsample_bytree=0.75, \ objective= 'binary:logistic', nthread=4, seed=27) n_estimators_lr = get_n_estimators(xgb4, train_3, predictors, target) |
训练并验证模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
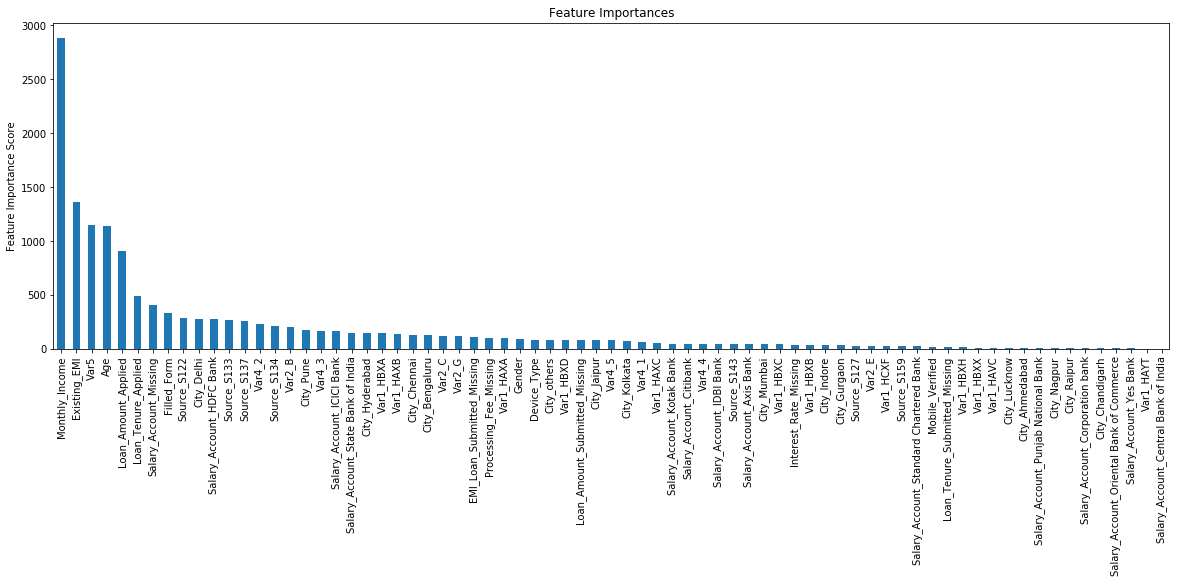
### 调试后的分类器 tuned_xgb = xgb.XGBClassifier(learning_rate=0.01, n_estimators=n_estimators_lr, max_depth=4, min_child_weight=6, gamma=0.2, \ reg_alpha=0.01, reg_lambda=1, subsample=0.7, colsample_bytree=0.75, \ objective= 'binary:logistic', nthread=4, seed=27) ### 训练模型 pipeline = Pipeline([("feature_engineer", pipeline_data), ("classifier", tuned_xgb)]) pipeline.fit(train_X, train_y) ### 特征重要性 feat_imp = pd.Series(pipeline.named_steps['classifier'].get_booster().get_fscore()).sort_values(ascending=False) feat_imp.plot(kind='bar', title='Feature Importances', figsize=(20,6)) #如下图所示 plt.ylabel('Feature Importance Score') ### 预测 print(pipeline.predict_proba(test.iloc[[1]][predictors_raw])) #individual prediction predprob=pipeline.predict_proba(test[predictors_raw])[:,1] #test data predictions print("AUC Score (Test): %f" % metrics.roc_auc_score(test[target], predprob)) #AUC Score (Test): 0.8572 |